
The data lake is essential for any organization who wants to take full advantage of its data. The data lake arose because new types of data needed to be captured and exploited by the enterprise. As this data became increasingly available, we use these data to discover insight through new applications to serve the business. We can then use a variety of storage and processing tools, typically tools in the extended Hadoop ecosystem, to extract value quickly and inform key organizational decisions.
Analyse and store petabyte of data:
CodeSizzler simplifies real-time data integration to Azure Storage solutions – including Data Lake Storage (Gen 1 and Gen 2) and Blob Storage – from a wide variety of sources.
You can continuously deliver data from enterprise databases via log-based change data capture (CDC), cloud environments, log files, messaging systems, sensors, and Hadoop solutions.
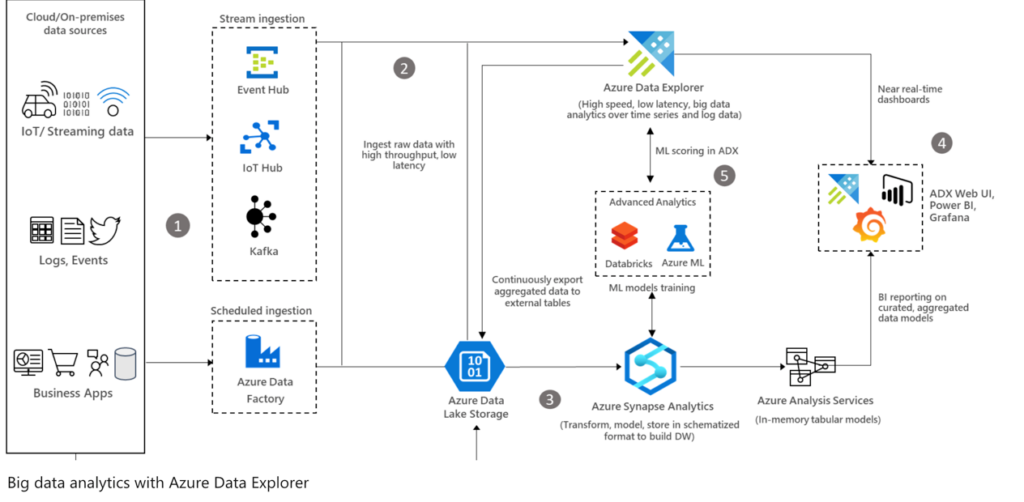
The CodeSizzler solution enables you to quickly build streaming data pipelines with your desired data potential (real-time, micro-batch, or batch) and enrich the data with added context. These pipelines can then support any application or advanced analytics / machine learning solutions – including Azure SQL Data Warehouse and Azure
Databricks – that use Azure Storage services. With access to prompt data in the right format, your data operations teams can significantly reduce the preparation effort for analytics, and your organization can achieve faster time-to-insight.
Enterprise Solutions
Manage your data
Data management
Data Governance & Integration
Data access
Security
Application development
Solution design
ETL
Data aggregation
Insights for smarter decisions
Use case discovery
Statistical method
Data modelling
Machine learning
Use case | Retail Analytics


